Big picture for the Project
This Project is divided into two parts. The first part is “an environment scan” of current researches on data provenance. The goal of this part is to solve the major question “how people use data provenance and what kind of data provenance tools have been used in the academic discipline”. The outcome for this part is an annotated bibliography. As for the second part, hands-on research and programming will be launched, with a report as the output for this part.
What is provenance
Provenance is a quite new concept. However, people encounter provenance almost every day. The definition of provenance differs from different fields. The definition of provenance in dictionary Merriam-Webster is “ ORIGIN, SOURCE” or “the history of ownership of a valued object or work of art or literature”. Regarding OPM (Open Open Provenance Model), the article (Luc Moreau et al.2008) illustrates that “Provenance is well understood in the context of art or digital libraries, where it respectively refers to the documented history of an art object, or the documentation of processes in a digital object’s life cycle.” While provenance in W3C is defined as a record that describes entities and processes involved in producing and delivering or otherwise influencing a certain resource. In the new discipline “blockchain”, provenance also has its particular meaning. Data provenance, which combined blockchain, is more likely a “Data Identity”, showing when the data was created, who collected the data, what kinds of operations had been launched on the data, etc. Nobody can change information of “Data Identity” and researchers in the future can easily track information of this data to assess its authenticity and do reproducibility.
Type of provenance
Herschel et.al (2017) explained provenance and classify provenance into four main types, namely Provenance meta-data, Information system provenance, Workflow provenance, and Data Provenance. The method to differentiate each type form others could be explained as follows. Meta-data itself can be regarded as provenance and operations related to it can also be seen as provenance. General meta-data tend to assign meaning on the data while provenance meta-data focused more on data derivation process. Based on the definition of provenance in W3C, data like the size of a file is not the provenance while the date of creation is the provenance. When we limit the context of provenance to information system, this kind of provenance could be called Information system provenance. Furthermore, by restricting the type of production process to so-called workflows which helps scientists conceptualize and manage the analysis process at each step, provenance becomes workflow provenance. Sometimes, scientists could use provenance to track the processing of individual data items, then this kind of provenance is called data provenance.
Provenance Model
In the previous research, several models have been established to standardize the requirements to create provenance and allow provenance to be exchanged through different systems. The main two models are called OPM and W3C PROV.
OPM
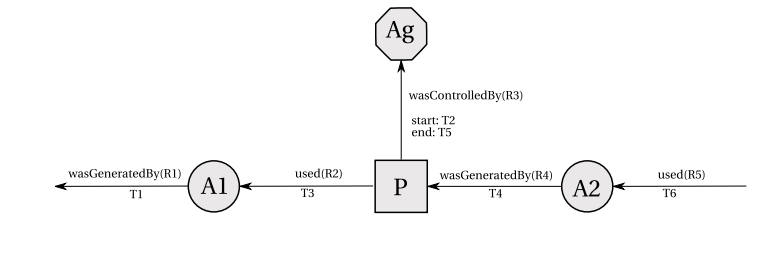
Figure 1 OPM Structure, retrieved from https://eprints.soton.ac.uk/271449/1/opm.pdf
OPM is short for Open Provenance Model, whose aim is to capture the causal dependencies between three concepts, namely artifact (an immutable piece of state), process (actions or series of actions performed on/ by artifacts), agent (Contextual entity acting as a catalyst of a process).OPM is often used to document the previous executions, in other words, the processes happened in the past and they have already ended; in addition, they can still be running.
To understand OPM easily, a graphical notation is often used. Specifically, artifacts are represented by ellipses; processes are represented graphically by rectangles; finally, agents are represented by octagons. In the graph, nodes represent processes, artifacts or agents and edges stands for casual dependencies between nodes.
W3C PROV
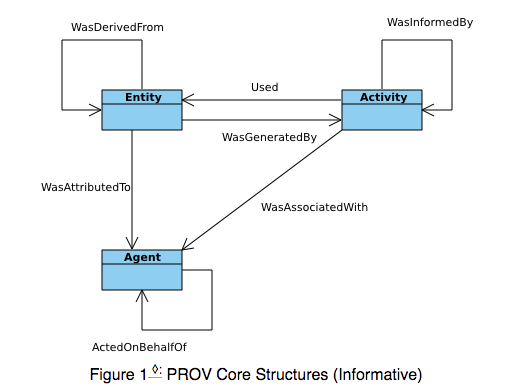
Figure 2 UML Diagram of PROV Structure, retrieved from https://www.w3.org/TR/prov-dm/
Different from OPM, W3C PROV used different terminologies and added more details to the previous models. In PROV, “type” and “relation” are used to represent the “node” and “edge”, furthermore, “entity” and “activity” are corresponding to “artifact” and “process” in OPM. Besides the existed relationships (Used, was generated by, was controlled by, was triggered by, was derived from ), two more relations were added (a dependency between agent and agent, a dependency between entity and agent). Additionally, Mapping of PROV core concepts firstly emerged, which made understanding much easier.
PROV ONE
PROV ONE is defined as an extension of the W3C recommend standard PROV, aiming to capture the most relevant information concerning scientific workflow computational processes, and providing extension points to accommodate the specificities of particular scientific workflow systems.
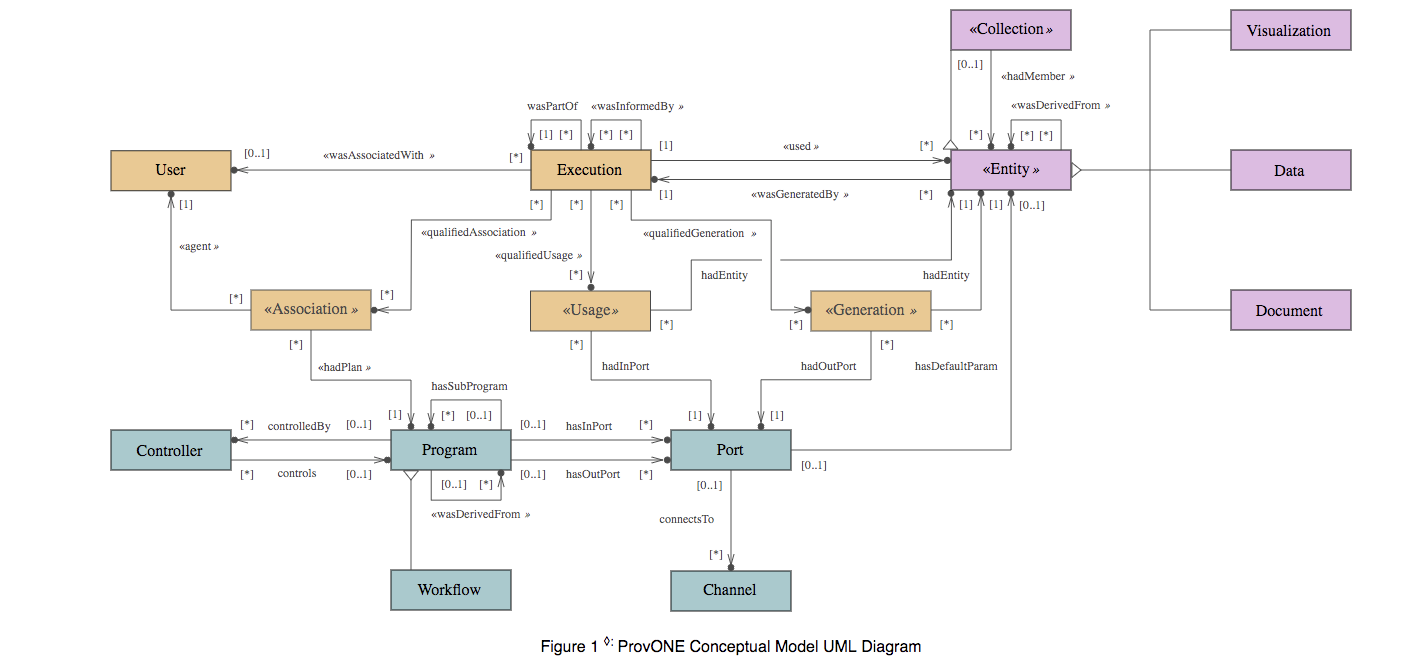
Figure 3 UML Diagram of PROV ONE Model, Cao, Y. at etc. (2016)
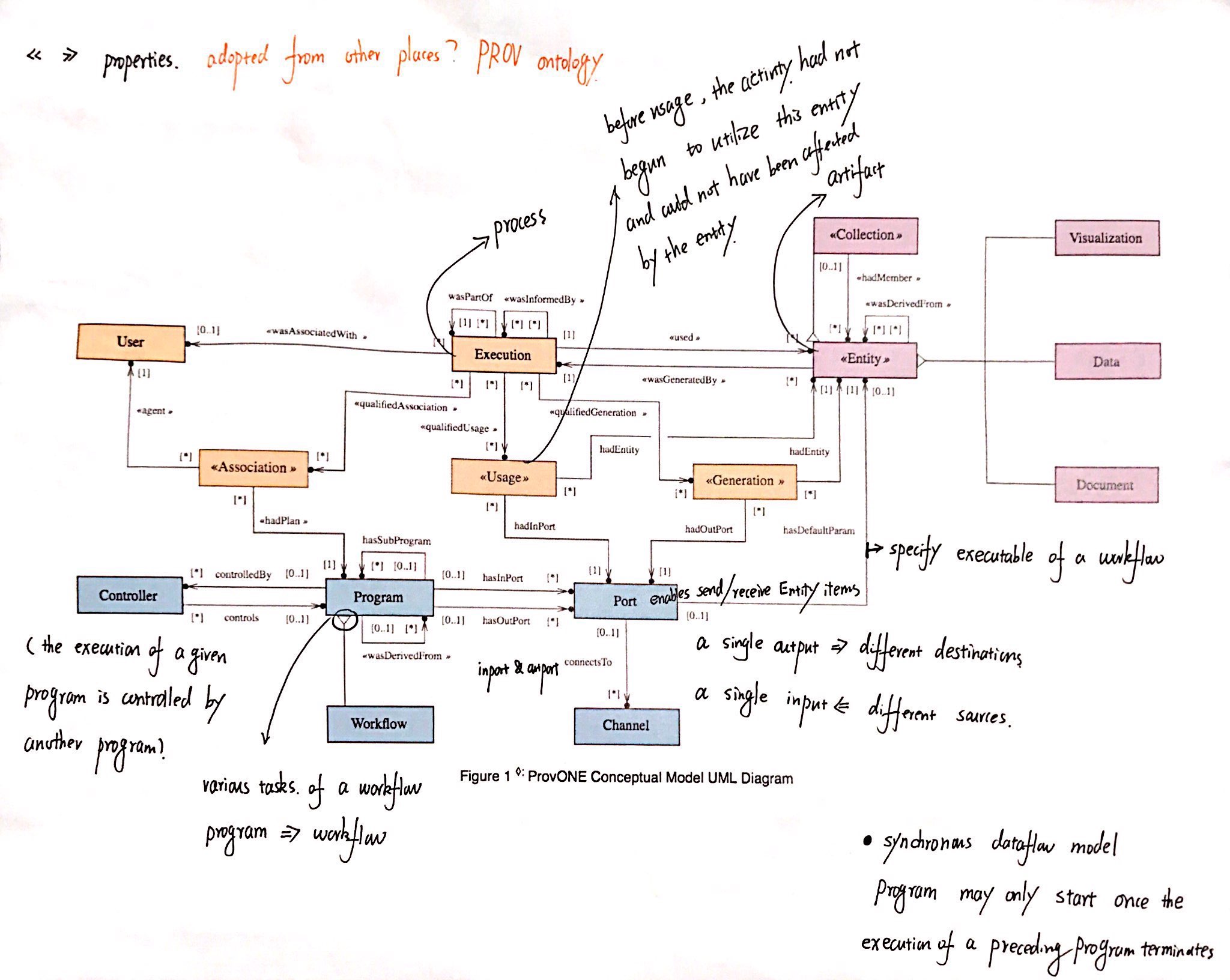
Figure 4 UML Diagram of PROV ONE Model ( Comments by Yilin )
Re-Clarify Research Question
Figuring out how provenance is used in academia can either help understand why experts use it or what can be done to improve current tools to better serve the scientific community. Though we did not find a good way to systematically identify all science papers that employ retrospective provenance information and standards (PROV or OPM), a large corpus of research papers (nearly 8000) is found using retrospective provenance, specifically Galaxy workflow and we further decided to explore the collection of Galaxy related papers, focusing on:
- A high-level exploration of the overall collection
- A detailed exploration of selected papers
Poster Presentation

Photo in 2019 DataONE AHM
